
This has been a long overdue article and it comes up in every customer conversation I have around GenAI. Since a lot of the use cases I deal with are people using GenAI against their documents, there is a real concern about security. They don't want their documents to be used by the LLM vendors to train on.
Then there was this post about GenAI being discussed at the Black Hat conference and that kept me up for a bit as statements like -
Gen AI cannot be used to secure Gen AI.
Gen AI is a very immature technology, and despite that companies are going all in without a clear understanding of the risks.
Nobody and I mean nobody knows how to secure it.
make me ask myself, am I being naive? Am I leading people down the wrong path (to be fair, I am very very very small cog in the big AI wheel that is leading people down the path).
I'll address both in layman's terms and hoping others who have a stronger security background will correct any misstatements I make.
If I use GenAI against my document, will this now be used to train the LLM -
Here is a visual that I find useful -
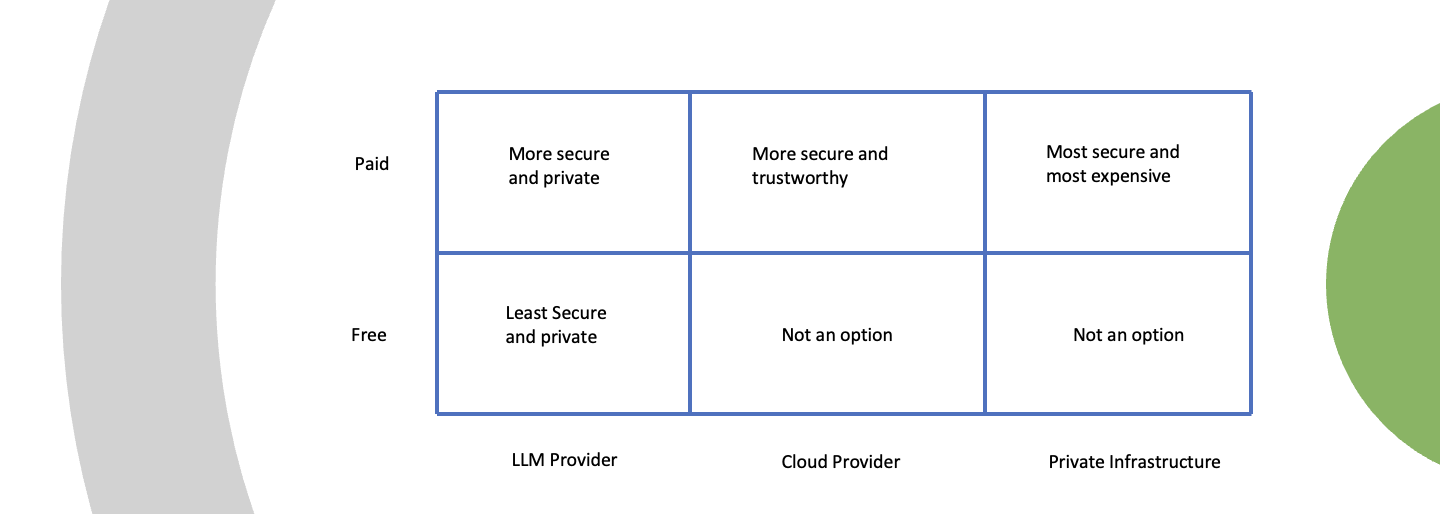
Bottom Left - The one option you should not be doing is using the free version of ChatGPT and upload private documents. This is the least secure option but it is the least expensive option, so I understand why people do it.
Top Left - If you use the ChatGPT Team/Enterprise or the API, OpenAI is very clear that they do not use your data to train the model. Similarly with Anthropic. "Anthropic does not use the data to train generative models.". "We do not use your ChatGPT Team, ChatGPT Enterprise, or API data, inputs, and outputs for training our models.".
Despite this, a lot of people want a higher level of security. I think the reason is - Do they trust Anthropic or OpenAI? These are multi-billion dollar companies that depend on this level of trust, but these are also early stage startups.
Top Middle - If you want a higher level of security, you can use Anthropic on Amazon Bedrock or OpenAI on Azure. Again the language is pretty clear - "Amazon Bedrock doesn't store or log your prompts and completions. Amazon Bedrock doesn't use your prompts and completions to train any AWS models and doesn't distribute them to third parties.".
If you want some more security you can access Llama (an open source model) on Amazon Bedrock and thus remove OpenAI from the mix.
In this case, it comes down to - do you trust Amazon or Microsoft. Considering all the other data we trust them with, why would this be any different. One thing I did find out is that there is a bit of a difference in the same model hosted by these providers vs what they natively host. I don't have empirical evidence, but it seems this way.
Top Right - If you want even more security, you can deploy your own open source LLM (Llama from Meta or Mistral). This will require you to have technical resources to set these models up, manage the hardware etc. So this is not a trivial decision.
The question facing most of my customers is they don't have the technical resources to go to the more secure options. That being said, if you are in this boat and want a no-code/low-code and secure GenAI option, check out www.anyquest.ai.
2. What about the - nobody knows how to secure GenAI and we are going to be in a world of trouble.
This is a deeper discussion and there is a lot more nuance and understanding that is needed. I will also say that I am not extremely knowledgeable about this topic but I will give my layman's understanding and how I am thinking about this.
Here is my framework -
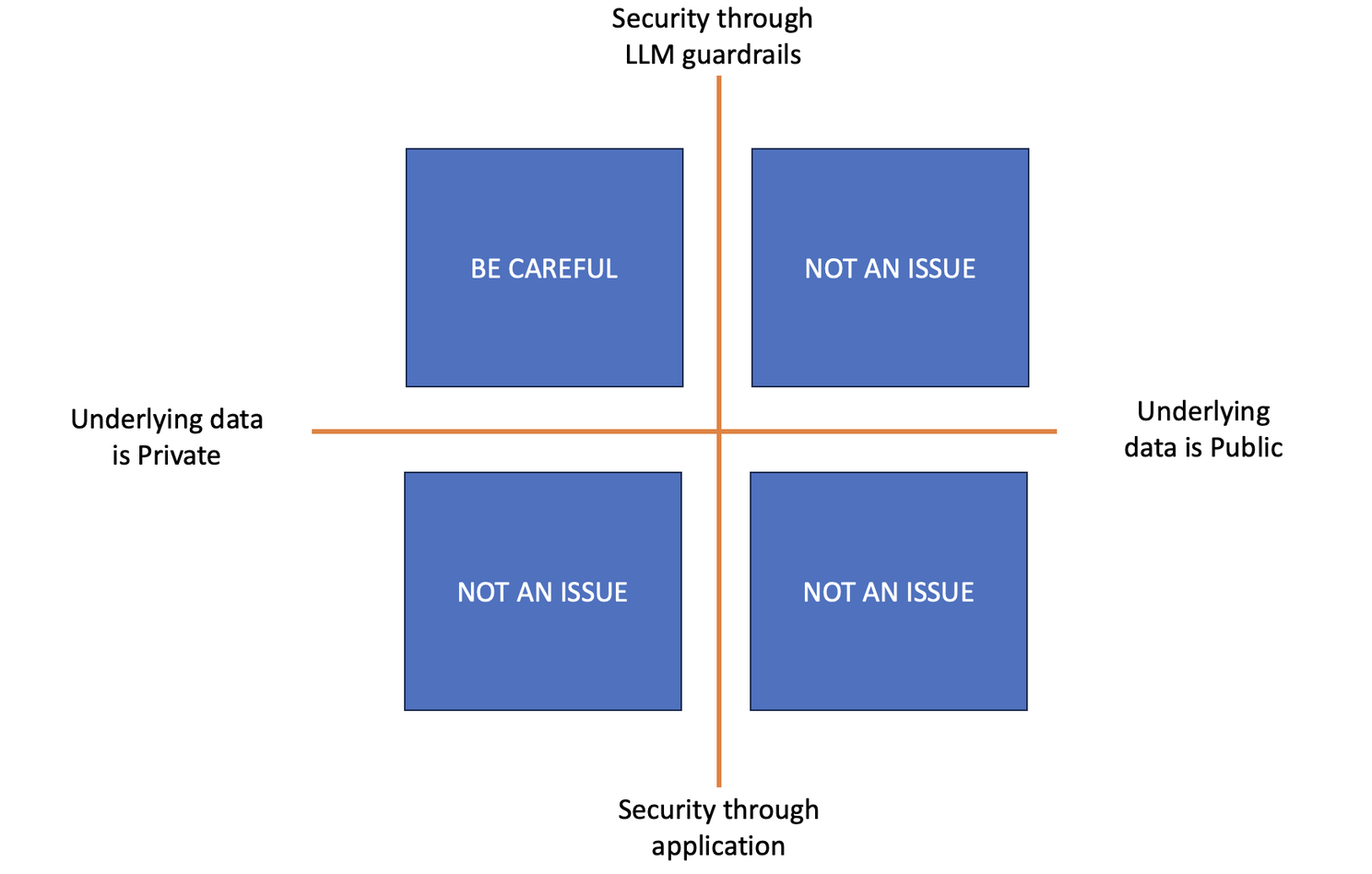
Firstly, I think about the underlying data being used by the LLM. If it is public data (doing account research on web data or person research using LinkedIn data), I don't think there is any reason to worry about security. All that data is already in the LLM (I am going to keep this away from ethics and focus on security).
If it is private data (your call transcripts, your CRM data, your knowledge base etc.), the question that becomes critical is how is this being secured. Here you have 2 options -
Control the security through the LLM via prompt guardrails. Let us say that I've built an application that allows users to ask questions off of a knowledge base of documents. I've uploaded all documents (including some sensitive ones about performance reviews that I only want some people to view). If I am implementing this security in my prompt, then this opens up security issues via prompt injection. Basically someone can add stuff to the prompt that could go around my security guardrails and potentially get access to this data. There are examples of this and people will keep trying to get around any guardrail based limitations.
If the security is being handled at the application layer, then we have much less to worry about. E.g with the knowledge base of documents example, instead of having one big knowledge base that anyone can ask questions from, I might have smaller knowledge bases that are accessible with specific UI and the UI controls who accesses which knowledge base. This does require more work and more thought. For example, www.anyquest.ai has a concept of workspaces, each workspace has its own security and you can point each workspace to it's own content repository.
The other axis to think about this is who is accessing the GenAI application.

If it is mostly an application used by internal users, you have less to worry about. Your risk is from an internal bad actor. Someone wants to access performance reviews and they are not supposed to. This gets you thinking about the use case and security should be considered always.
If you are building a public GenAI application (e.g. public chatbot, public agent) you have to be extremely careful as there are bad actors out there who will try and exploit any loophole. Sanchita Sur was kind enough to educate me about this some time back.
I think as GenAI agents become more popular, they will be the ones we have to be most careful and worried about as they have power to execute workflows and a public agent can be manipulated. Now you don't just have to worry about sensitive data, you have to worry about malicious actors doing malicious work.
So how do I feel - all my use cases are internal only for internal users. So this has absolutely reduced my concerns as we have a lot more control. Secondly, most of my use cases leverage 3rd party tools like www.anyquest.ai as a layer around the APIs, so there is an extra level of security built in. AnyQuest does security at rest, security in motion and it uses the APIs to make the calls. Lastly, I can control security at the application level with Workspaces.
Overall, I am glad that I read the post about Blackhat as it made me dig a bit deeper into a topic I needed to get deeper into. Thanks to Dmitri Tcherevik for taking the time to go through some of this with me.