
Mixture of Agents (MOAT) - A Two Part Series is sponsored by Agent.ai - Discover, connect with and hire AI agents to do useful things.
Google recently announced AI Co-Scientist last week and someone who builds agents I was fascinated by what they have created.
A multi-agent AI system built with Gemini 2.0 as a virtual scientific collaborator to help scientists generate novel hypotheses and research proposals, and to accelerate the clock speed of scientific and biomedical discoveries.
They talk about how modern breakthroughs have emerged from trans disciplinary endeavors but this creates a breadth and depth conundrum. How can someone know a lot about one topic (depth) but then also know enough about other related topics (depth). The example they share is about CRISPR, which combined expertise ranging from microbiology to genetics to molecular biology.
So they set out to challenge this need for depth and breadth and obviously AI was the solution but the way they solved this was with a multi-agent system.
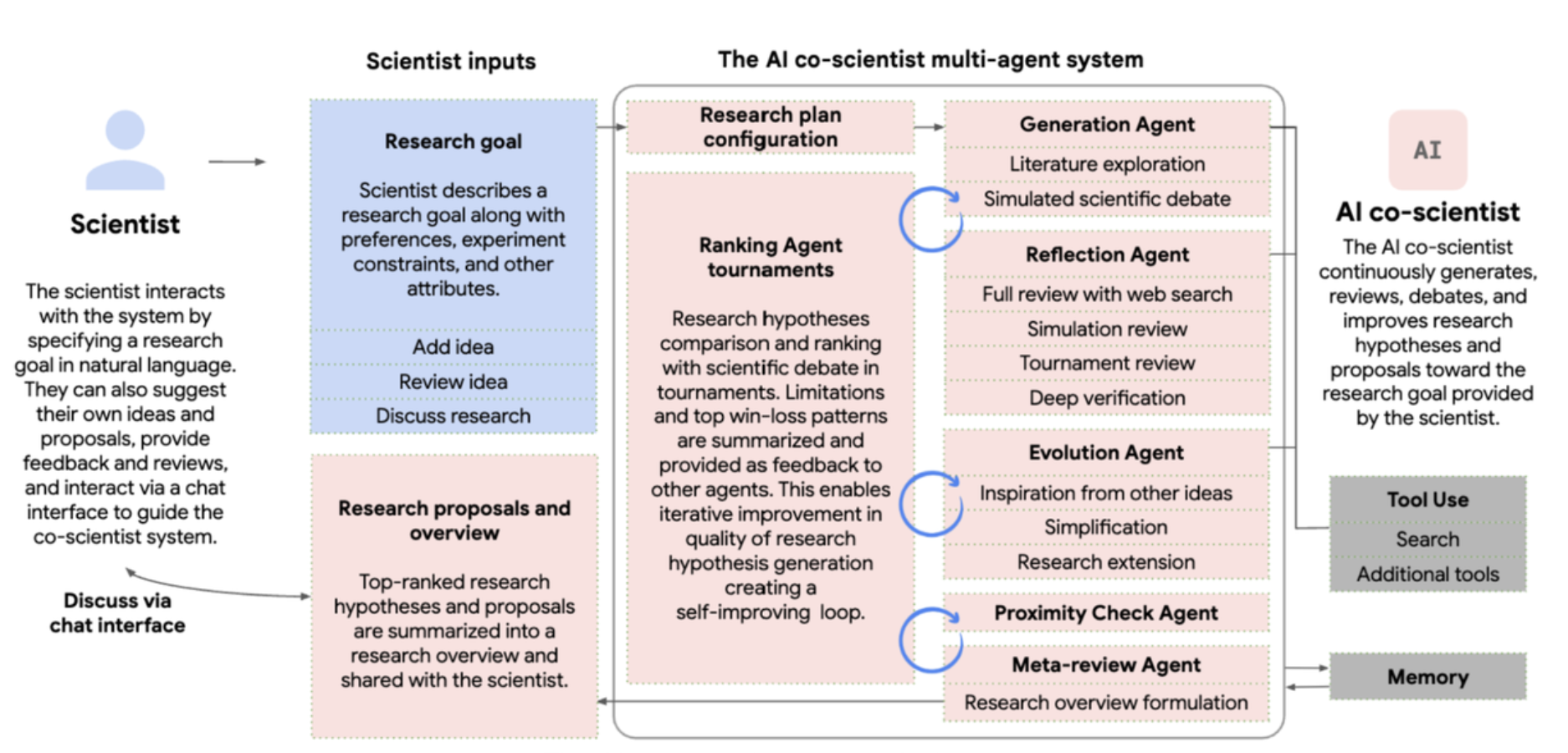
BTW, this is not something theoretical, but it has already started having an impact.
Professor José R Penadés and his team at Imperial College London had spent years working out and proving why some superbugs are immune to antibiotics. He gave "co-scientist" - a tool made by Google - a short prompt asking it about the core problem he had been investigating and it reached the same conclusion in 48 hours.
So, how does a Multi-Agent system look like in Go-To-Market (which is my focus)? In the Google example the underlying data was documents and the main tool needed was search (I assume web search and knowledge base search). In Go-To-Market, any real and practical examples, need data from multiple systems. There are very few workflows in GTM that can be solved with just web search. The second nuance is that in GTM, there are tons of workflows that depend on us working on lists of things (list of leads, list of prospects, list of customer, list of events, list of calls, list of opportunities). Also, the work that needs to be done on an item in the list is often not the depth of research that Google demonstrated.
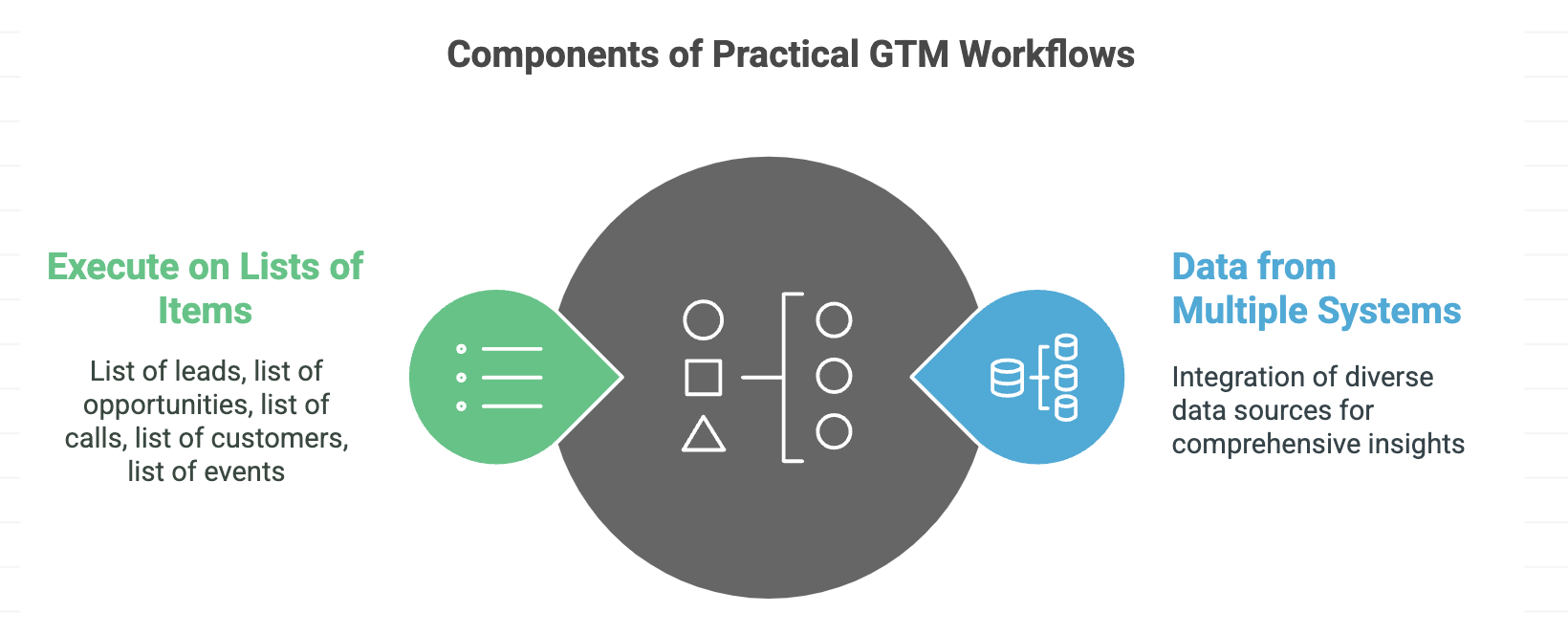
Both of these provide unique challenges to the 'DeepResearch' approaches of the LLM vendors. Try giving DeepResearch a task that involves working on a list of 100 items and it will clog up. Try giving DeepResearch a task that requires accessing structured data in systems and it won't work.
So the Multi-Agent system in GTM looks quite different as each agent can be hosted by a different company. For example, a Salesforce agent, collaborating with a HubSpot Agent.ai agent, collaborating with a Gong agent etc. orchestrated by say a tool like Clay. Whether we like it or not, we are not going to have 2 dominant Agent Marketplaces or App Stores like we have with mobile or a handful of dominant cloud providers like AWS, Azure, Google. We will have a very distributed ecosystem of Agent marketplaces and providers.
The agent world will look a lot more like SaaS applications and APIs that are owned and operated by thousands of vendors.
Recently, a friend of mine had a specific need. He had a list of 150+ companies he was looking at and he wanted to know if they had open jobs for certain roles he was interested in. His current process was to take the company and the role and search on Indeed / LinkedIn / Google etc. and then collate that list in Google Sheets. Needless to say this process would take a long time and is extremely tedious. Plus he had other friends who had a similar need and their list of companies and roles were different to his. He wanted to know if I could help him with this need.
So I took 15 companies and put them into DeepResearch and asked it to generate an output and it returned a fairly accurate list. When I gave it all 150 it did not work. This points to the working off lists problem that LLMs and DeepResearch have. I assume at some point they will build in list handling but for now this was not a scalable option.
So I took a step back and gave some thought to what a Multi-Agent system would look like and I came up with an architecture that combined Clay.com + Agent.ai. Technically I could have solved his entire use case in Clay.com but that would have eaten up a lot of credits and those of us that work with Clay.com live and breathe the fear of credits.
Agent.ai has a unique business model in that they realize this multi-agentic system is the future and that agents have to communicate across products. They are also looking to build the largest marketplace of builders and users and being incubated by HubSpot have deeper pockets than most startups. So they have made execution of their agents free (for the near future).
You can build an agent on Agent.ai and call it from Clay.com and you don't incur any cost. Agent.ai went one step further and even exposed their GetData and Use AI actions for free. So you don't even have to build an agent on Agent.ai to get access to the underlying data sources they expose.

In GTM, building any kind of practical agent requires access to data - LinkedIn data, Earnings Data, Web Data, YouTube channel data, News Data etc. and Agent.ai is making that data available to every builder.
So I loaded all the companies my friend sent to me into a Clay.com table, I enriched that company data by calling an agent on Agent.ai (instead of paying for Clay credits), then for each company I look for job listing for specific roles and return either a link to the job or make a note that the company is not advertising for the role. Here is a video showcasing this.
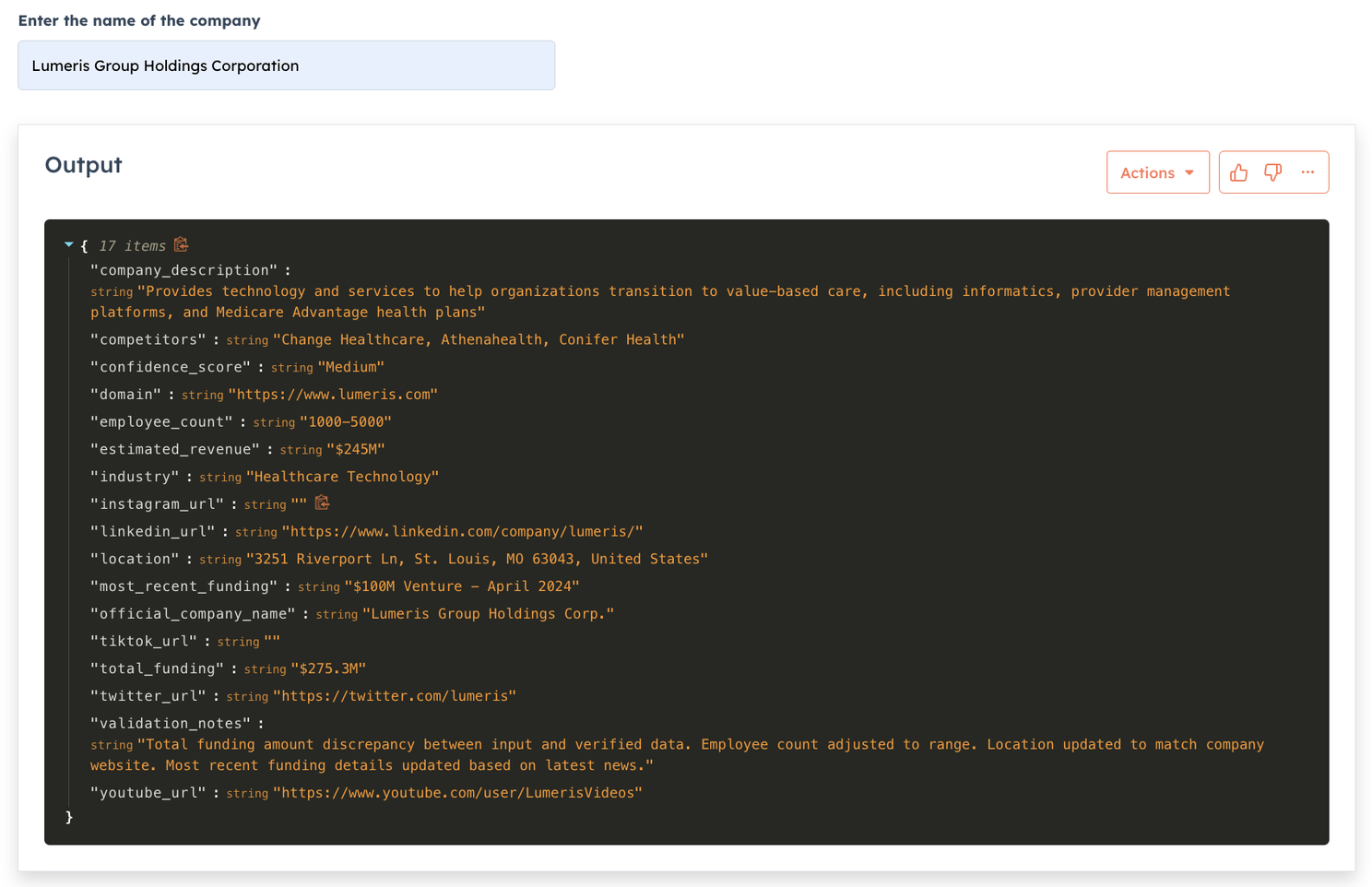
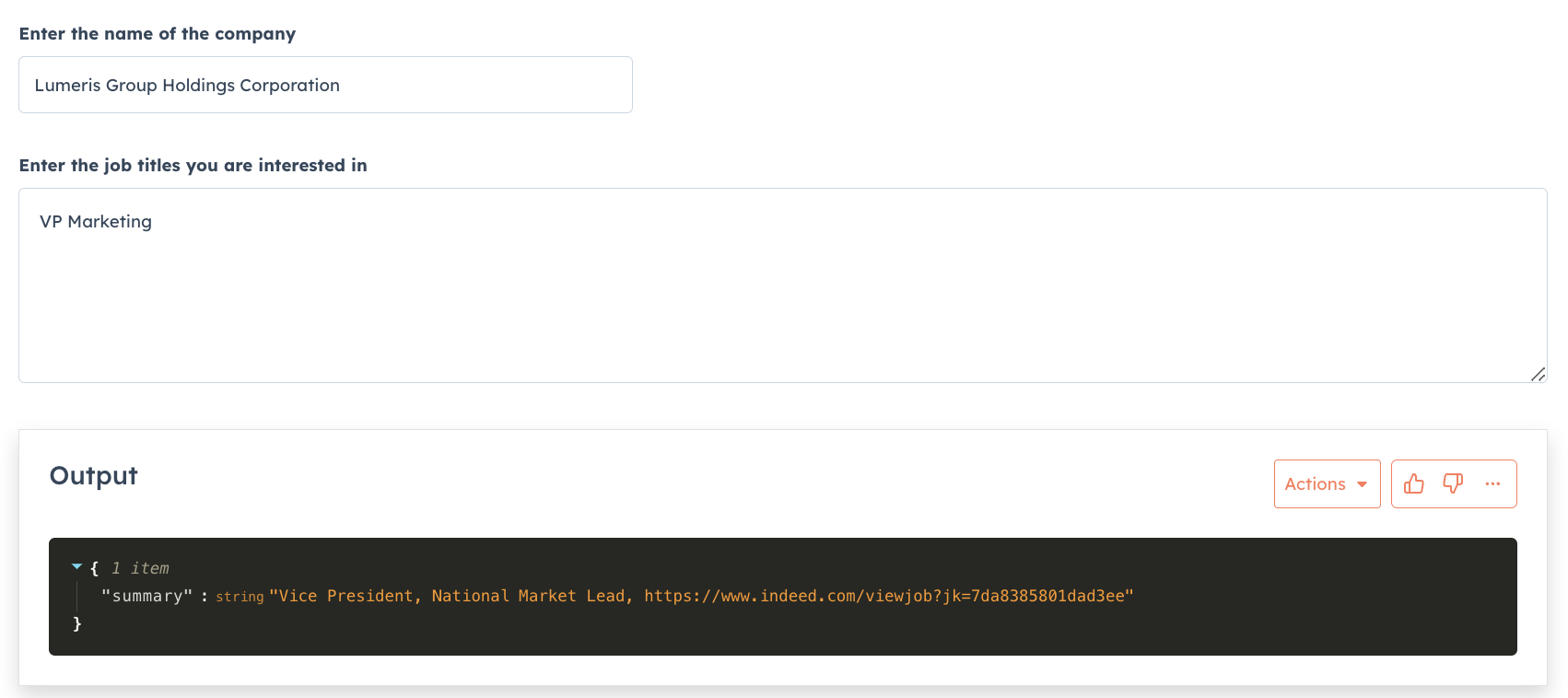
So far there is nothing special here. These are very simple agents (and can easily be built in Clay.com if you are willing to pay credits or use your own AI API keys).
What Clay.com brings to the table is the ability to execute this on a list of companies.
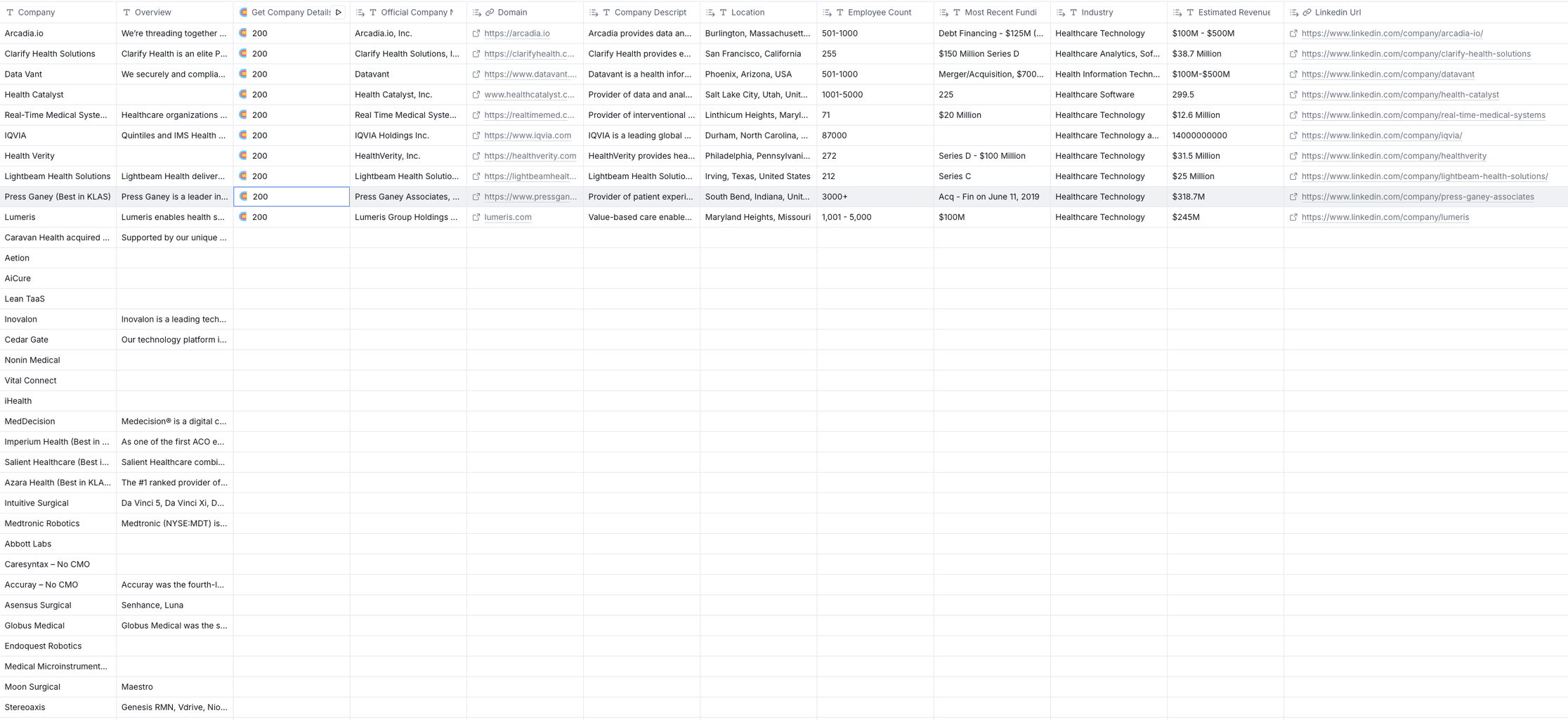
I can now call my Agent.ai agents via Clay's HTTP API functionality as Agent.ai makes every agent available to be called via a Web API. I just enriched about 10 companies but you can see the level of detail I can get for free.
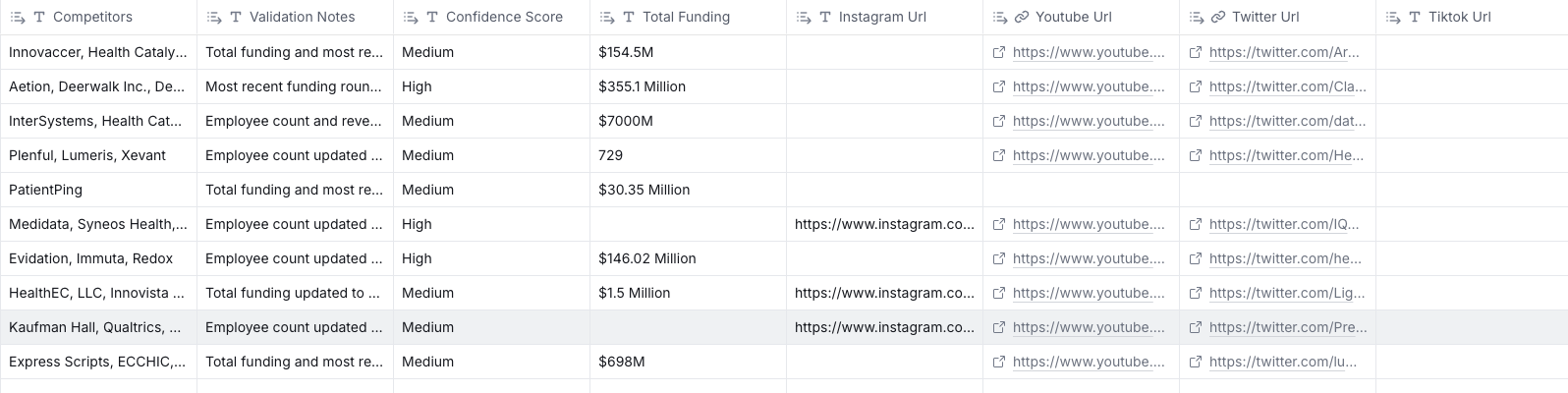

So I was able to do all this without using any Clay.com credits. That being said, there is one important consideration. My Agent.ai agents are using Perplexity and web search to get this data. While the data about the company is available on the public domain and I have high confidence that it is accurate, the job listings data needs more testing. I am asking Perplexity to find these jobs at these companies. As you can imagine using Perplexity search to find jobs can bring in errors.
If I want to have more confidence in my job searches, I have 3 choices -
Agent.ai adds a new GetData API call that searches for Google Jobs or LinkedIn Jobs or Indeed Jobs.
I use Clay.com's job enrichment and pay Clay credits.
Indeed or LinkedIn or other job boards make their data available via API and we use that.
The point here is that, this is the big advantage of a Multi-Agent system. If there is a better provider for a particular service, I could access it from Clay.com or Agent.ai and I can solve problems by orchestrating across platforms.
The one big problem that needs to be addressed with Multi-Agent systems, is reliability of the Agent that we have built. With these many moving parts, my agent can fail/run slow because any one of the underlying services is not reliable my entire agent is reliable. It comes down to the weakest link in the chain.
So my call to action for anyone who has got this far is to go sign up for Agent.ai and start building some agents and create your own multi-agent system.
